What can we simplify in enterprise-architectures?
A great conversation this morning with Nigel Green, about his post ‘When is striving for Simplicity in IT-EA a good thing, and when…?‘ (“…is it less important, or even unhelpful?”, was the completion of the sentence).
He’d been having a long discussion with another well-known figure in the IT-architecture space, who’d insisted that we should always aim to simplify. Nigel was uncomfortable with that assertion, in fact was all but certain it was only true under specific contexts, but wasn’t sure how best to describe those contexts or the differences between them.
At that point he turned to the diagram from his previous post ‘A thinking framework for Business/IT ‘Systems’ behaviour based on Cynefin‘:
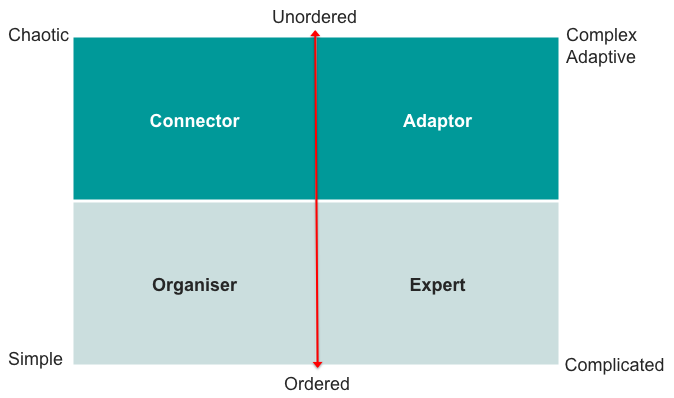
As you’ll see from his ‘Simplicity in IT-EA’ post, he then started filling in more detail about what each of those domains would look like in terms of IT-applications:
- Organiser (‘Simple’) – “most IT sits here: Office + ERP”
- Expert (‘Complicated’) – “CAD/CAM, rules-engines, complex-management systems”
- Adapter (‘Complex-Adaptive’) – “sense-and-respond systems, ‘complex event processing’, BPMS”
- Connector (‘Chaotic’) – “web + social-networks”
Which is a very useful way to split up the IT space.
But if we have just one domain called ‘Simple’, is that the end-point of all simplicity? Could everything become defined by simple rules? Could everything ultimately be reduced to definable IT? That other well-known figure clearly thought so. But Nigel didn’t; and neither do I. To explain why, I’ll quickly summarise what Nigel and I talked about in our conversation.
Some of the same themes can be seen in my previous post ‘Backbone and business-rules‘, which also points to Nigel’s earlier post above. Perhaps the key point is a slightly different way to use the Cynefin-categorisation, emphasising what we use for decision-making within each of the domains:
- Simple – rule-based
- Complicated – algorithms
- Complex (‘Complex-Adaptive’) – patterns and guidelines
- Chaotic – principles
The crucial factor here is that there are fundamental differences between each of the domains.
In the Simple domain, cause/effect relationships are linear, and direct: we can use simple rules to drive decision-making. Simplification here consists of finding ways to reduce the number of rules, and to remove any duplications or conflicts.
In the Complicated domain, cause/effect relationships are still linear, but may be indirect, with multiple interacting factors, feedback-loops and delays. We can still use linear true/false logic – the kind that almost all computers use – but we can’t reduce it to simple rules: we have to use algorithms, and those algorithms can become very complicated indeed. Simplification here consists of cleaning up the algorithms, and identifying ways to simplify relationships between all the various factors: but again, it can’t all be reduced to simple rules.
In the Complex domain, at least some of the cause/effect relationships are non-linear: cause and effect become intertwined, and to some extent interchangeable. We shift from a simple true/false logic to a modal-logic (alethic logic of possibility, probability and necessity), with decisions guided by statistical patterns or more fluid guidelines. IT-systems shift from decision-making to decision-support, such as pattern-matching for final decision via ‘human-in-the-loop’; IT-based algorithms may be used for the pattern-matching, but cannot (or should not) be used for the final decision-making itself. Simplification here consists of refining the patterns and pattern-matching algorithms, and developing and refining training, education and guidelines for the human-element in the decision-making.
In the Chaotic domain, no distinct cause/effect relationships can be identified – typically either because the event is in some way unique or non-repeatable, or because it occurs at or near real-time, without sufficient time to assess causal links. Because there is no apparent repeatability, attempts to use true/false logic make no sense; decision-making is typically via principles or some other equivalent ‘guiding star’. Decision-making here will always require ‘human-in-the-loop’. The main role of IT-systems here tends to be information-capture and presentation: they cannot (or should not) be used for decision-making here, other than perhaps by inserting deliberate randomness into a human decision-making process to disrupt inappropriate assumptions and other ‘pattern-entrainment’. Simplification here consists primarily of clarifying information capture and display (decision-journey, user-experience, infographics etc), and of refining the applicable principles by identifying and clarifying priorities, conflicts and the like.
In the ordered domains (Simple and Complicated), repeatability can be eventually guaranteed, although varying levels of difficulty (‘complicatedness’) may be needed to achieve it. Einstein’s dictum applies here: we would be crazy to do the same thing and expect different results. In these domains it is possible for decision-making to be entirely IT-based: to many people, this brings a satisfying sense of ‘control’ over the context.
In the unordered domains (Complex and Chaotic), repeatability can not be guaranteed, regardless of how much effort is put into the analysis. (The distinction between ordered and unordered domains is qualitative, not merely quantitive: despite the assertions of many IT-folks, true complexity in this sense is not the same as ‘very complicated’.) Einstein’s dictum often becomes inverted here: we would be crazy to do the same thing and expect the same results. Any notion of certainty or ‘control’ here is illusory at best, and often a dangerous delusion. In these domains it is not possible (or rather, it is usually unwise) for decision-making to be entirely IT-based: efforts to ‘simplify’ by attempting to remove all ‘human-in-the-loop’ elements will often convert an already difficult problem into an irresolvable ‘wicked-problem‘, and will always make things worse.
Note that very few real-world contexts will fit solely within one of these domains; most contexts will include elements from all of them. One of the first requirements for simplification in IT-architecture or a broader enterprise-architecture would be to identify which elements of the context are in which of these domains – Simple, Complicated, Complex, Chaotic – and apply the appropriate simplification-techniques to each. Using one domain’s simplification-techniques in a different domain will usually make things less simple: if a context seems to be becoming more complicated, complex or chaotic, it’s probable that the wrong type of ‘simplification’-technique is being used.
Hello Tom,
I disagree with the analysis model.
near the end of your article, you state “Note that very few real-world contexts will fit solely within one of these domains.”
I would start with that statement, and then say that the analysis model is insufficient to address the problem.
I agree with your position: that simplicification must be addressed in different ways, depending on environmental factors. One correlary to your analysis: simplification can actually become a fools-errand, with one initiative after another targeted at simplifying the “symptoms” (IT infrastructure) without addressing the “cause” (business structural and rules complexity). You described the right solution… address the real source of complexity… but I cannot say that your approach is typical.
But I don’t agree that the simple “quadrant” model is going to connect well either with IT porfolio managers, Business technology stakeholders, or IT architects.
I don’t approach the problem from this perspective. Rather, I approach complexity and simplicity from the approach of “differentiation” vs “commodity” on one axis, and “shared information” vs “unique information” on the other. What goes on the grid: business models. This allows an understanding of which business models naturally group together, and allow opportunities for simplification.
I’ll see if I can post the mechanism on my blog for comment.
Thanks for your post.
@Nick Malik – Perfectly happy with your “I disagree with the analysis model” 🙂 – though I’ll have to admit I’m not sure quite which part you;re disagreeing with: the original Cynefin framework, Nigel’s cross-map to applications-types, his subsequent cross-map to issues around simplification, or my follow-on in this post?
For the original Cynefin, do take a look at the Wikipedia page, and from there follow the links to the Cognitive Edge website and the Snowden & Boone paper in HBR, which has proven very popular with business-folk. I ought to point out that Cynefin is not a simple two-axis ‘quadrant’-type framework: its presentation is often (over)-simplified to that kind of layout for practical reasons, but there’s a lot more depth to it than that. To give just one example, one of the drivers in Cynefin is that the ‘Chaotic’ would in practice always end up in the ‘Complex’ space: there’s a lot more detail in the HBR article and on the Cognitive Edge site, anyway.
For Nigel’s articles, please follow the links above. Both posts are fairly short, but there’s enough detail to describe Nigel’s thinking and reasoning on why he’s used that particular frame.
The post above is essentially a record of a fairly long phone-conversation that I had with Nigel, describing my own ‘take’ on his concerns about the way his colleague viewed simplification. One point I didn’t include above, and should have done, is how simplification-efforts ‘move’ a context between Cynefin-style ‘domains’: for example, ‘Chaotic’ to ‘Complex’ as above, and also ‘Complicated’ to ‘Simple’. The whole point of ‘simplification’ is that it moves the context in some way, thereby changing the relative proportions of each domain as applicable to the context – yet it’s probable all domains would exist in some form in all real-world contexts. In other words, it’s extremely improbable that we would ever be able to reduce everything to the Simple rule-based view of the world – even though that would seem to be the declared aim of ‘simplification’. [Hmm… reading back, I’ve probably rendered that even more confusing than when I started… apologies… 😐 ]
There’s another whole area that we would need to discuss on this, around how governance will be different in each domain. That’s an aspect of the architecture where I know you would have much of value to say: so please do? 🙂 Also would very much like to see more on your own view of simplicity vs complexity: another blog-post somewhen, if you would?
Many thanks, again, anyway.
Hi Tom.
Thanks for the article – some thought bubbles for me (as a non IT person fitting into the ‘clumsy user’ space) are
Simple: ‘guidelines’
Complicated: ‘Rules based’
Complex: ‘Algorithms’
Chaotic: ‘patterns and non patterns’
As the user, simple is what works without me needing to think too heavily about it – ‘rules’ rarely allow me to do things simply, though they may simplify by offering me a checklist to follow. That makes them structured but not simple. So a guideline would be something that works generally well enough for me not to have to think too hard as a user and fits in with your idea about simplification being addressed in different ways
Complicated therefore embraces the rules structure as in ‘if this, then that’ and ‘if not this, then that, or that or not that’
Complex – for the algorithms, is where as a user, my head hurts 🙂 In this space I sense that complex means that what ever is happening is knowable to me, and that I’d need much effort to gain a serious understanding
Chaotic is for a user where sometimes I see a pattern, sometimes I don’t. Only the very few would discern the potential what and how from amid the morass of outputs
Just my non informed view!
Marcus
Hi Marcus
Wow – this is great! 🙂
As my colleague Kevin Smith puts it, there are two ways in which people get things ‘wrong’. One is that they haven’t thought about it, and are being just plain stupid: we all suffer more than enough of those. 😐 But the other way is that someone comes at it from a completely different direction – perhaps casually, but with real insight – and lights up whole areas that we’ve previously missed. This is definitely one of the latter type… hence many thanks indeed.
I’ll do a separate blog-post on this later today, but the quick one-liner for now is that (for me at least) you’ve hugely highlighted a crucial difference between a machine-oriented perspective and a human oriented one: machines find rules Simple and guidelines impossibly Complex, whereas for real people it’s the other way round.
Hmm… wow….
Thanks – more later! 🙂
– tom g.