Applications, work-instructions and business-continuity
For business-continuity after disruption or failure, what’s the first thing we’ll need? Answer: an alternative way to do things.
For business-process redesign, what’s the first thing we’ll need? Answer: an alternative way to do things.
In both cases, we’ll need an enterprise-architecture that can support alternative ways of doing things.
Or, more specifically, doing the same nominal things in different ways.
Which we could summarise visually like this:
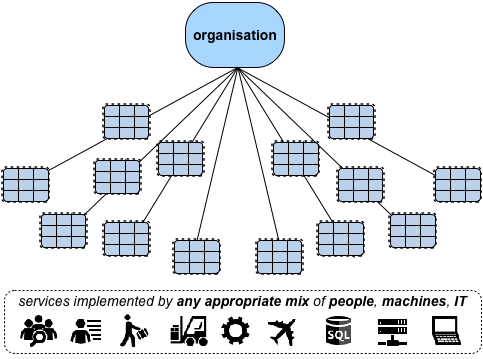
For many key concerns such as business-continuity, we must be able to switch between alternative ways of working – and to do so as seamlessly as possible. To use a more formal term, implementations need to be as fungible as possible – and, wherever practicable, with those different implementations hidden behind much the same interface, such that on the outside it still seems to be the same application.
But that’s where we hit a problem.
All of our current mainstream ‘enterprise’-architecture frameworks and notations are IT-centric. They don’t support the whole of the scope in that graphic, that point about “services implemented by any appropriate mix of people, machines and IT”. Instead, they support only the small subset of it that is specific to IT – as per the infamous ‘BDAT-stack‘ of Business, Data, Applications, and [IT] Technology:
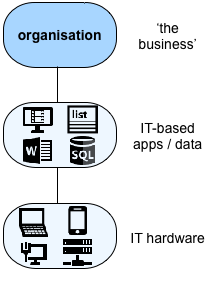
That means that they can support fungibility if and only if the alternative implementation is IT-based. There’s no built-in way to make any other form of implementation visible.
Which is perhaps not a problem if, for example, the fungibility we need is towards IT-based business-automation.
If.
But it’s a huge problem if we’re planning for business-continuity and disaster-recovery, where it may well be the computer-based IT that is out-of-action, and we need to replace it with something else. For that kind of context, an IT-centric EA framework is actually worse than useless, because it actively hides any non-IT alternatives that we might have. For example, because the BDAT-stack above, embedded within common ‘EA’ notations and frameworks, assumes that all processes are enacted by IT, it forces us into some truly horrible conflations – such as asserting that anything human exists only in the Business layer, and anything physical only in the Technology layer:

Yes, it’s a convenient simplification for anyone who works only in an IT-specific context. In practice, though, this does not work for most other real-world contexts – which makes it seriously problematic for anyone other than the IT-only folks. For example, in business-continuity and disaster-recovery, we are very likely to need ‘human applications‘ – such as the manual use of a physical sales-ledger to substitute for the out-of-action IT-system in the Starbucks example referenced above.
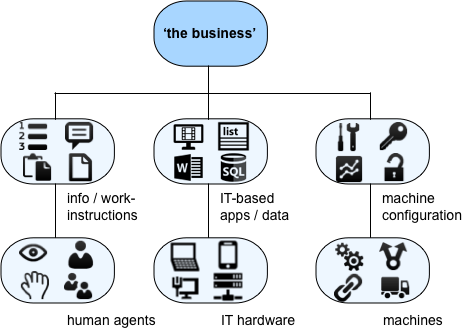
To make sense of what’s actually going on, and what’s actually needed for real-world business-continuity and the like, we need to make the layer-split in a completely different way – one in which human-based, IT-based and machine-based implementations are essentially fungible with each other, and where we distinguish only the instructions for action (‘apps/data’), from the related agent (‘technology’) that will enact those instructions:
We could also usefully distinguish between what is being worked on – information, in this case – from how (the instructions) and from by-whom or by-what (the agent) that is acting on that ‘what’:
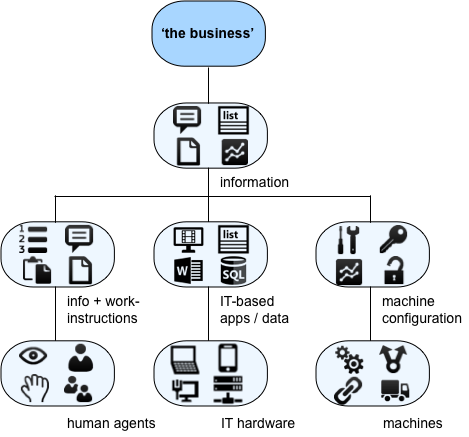
Each type of agent – human, IT or machine – may well need its instructions and/or data provided in a different form: for example, a human agent will need work-instructions rather than application-code. But in essence they’re the same – and they need to be so.
There is a vast array of real-world examples of this. Some of the most interesting are in the physical world, such as how the shape of a physical key is actually data encoded in physical form as instructions for a lock, or how a centrifugal governor is effectively a mechanical control-application for a steam-engine. Digital technologies can be implemented by all manner of physical means, such as in ‘fluid logic’ or fluidics, or even powered by falling marbles. Other physical ‘applications’ may be programmed via mechanical configuration, via topology (video) or even via biochemistry at nano-scale. And whilst, yes, some kind of IT-application may be involved in many cases, we would miss the point badly – even dangerously – if we focus in only on the IT-application. At the architectural level, we need to view each process across all of its possible implementations – and not constrain ourselves to one arbitrarily-chosen type of implementation, as is so endemic in IT-centrism.
To summarise, work-instructions are applications – applications to be implemented by a human agent rather than an IT-based one, but in every other respect an ‘application’ in exactly the same sense as in IT. Or, to put it the other way round, IT-applications are work-instructions for an IT-based agent. The only thing that’s different is in how those work-instructions are implemented and enacted: in every other regard, they’re essentially the exact same thing – and need to be understood as such.
They’re the same thing. That’s the point we need to hammer home here. If we don’t understand this point, we’re likely to constrain our options and more when we need fungibility for business-continuity and the like – constraints that could literally be lethal if we don’t take the right kind of care.
Just one more reason why, for everyone’s sake, we must get rid of the endemic IT-centrism that cripples so much of current enterprise-architecture. An IT-centric ‘enterprise’-architecture, that can only address the IT-specific parts of the overall enterprise and forces us to ignore everything else, is often worse-than-useless for many real-world needs. Enterprise-architecture only becomes real, and useful to all, when it can address the entirety of the enterprise, in all of its implementations – not solely the easy IT-only bits.
Leave a Reply