How architectures fail – 2: Scope of action
How do architectures fail? One way is that we start architecture too late or finish too early on the realisation-stack – so how do we avoid that trap?
My recent webinar ‘How architecture fails, and what to do about it‘ (see slidedeck on Slideshare, and full 90min video via link on this post) explored three common causes of architecture failure:
- 1: Blurring between distinct roles of architecture and design
- 2: Starting architecture too late and/or finishing too early [this post]
- 3: Placing arbitrary constraints on content, scope and/or scale
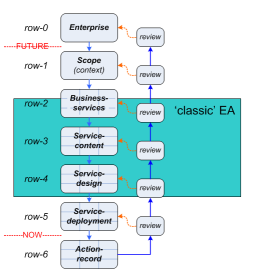
As in the previous post, we’ll explore this fail using a modified version of the Zachman rows as a common reference:
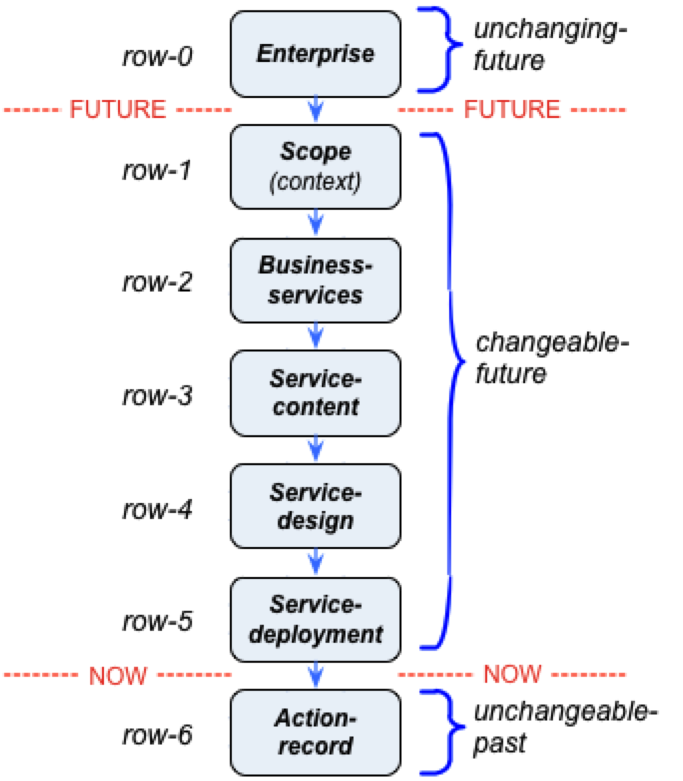
…where each row (or layer) downward adds further specific detail as we move towards the real, the ‘Now’ of action:
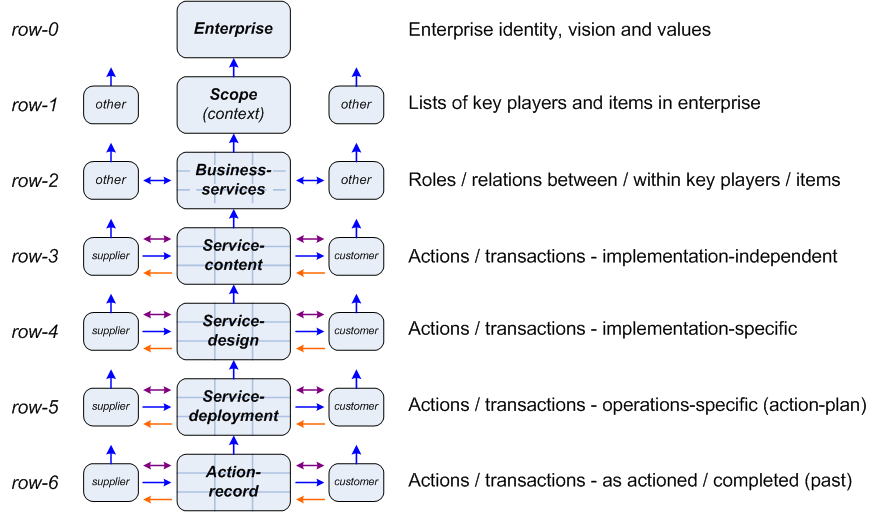
Note that this isn’t just a simple top-down sequence: instead, as described in the previous post, we switch back and forth between the distinct perspectives of architecture and design to iterate up and down the realisation-stack, as we identify boundaries, drivers and priorities for choices (architecture) and test new options (design). Yet there’s a twofold danger here:
- we may begin that process of iteration too far down in the stack – start the architecture too late, skipping over the work that needs to be done in the upper layers of the stack; and/or
- we may finish that process of iteration too far up in the stack – providing no architecture-guidance for the final stages of design, build and operation
Enterprise-architecture in particular must address the whole of the realisation-stack – connecting together all of the different groups of players in the respective enterprise-story: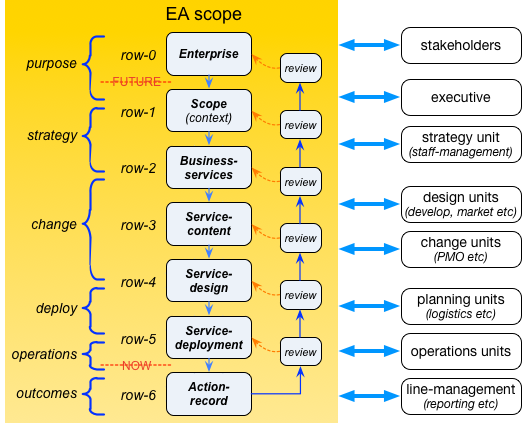
If we don’t do this, the overall architecture will inevitably fragment into a mess of unconnected elements, riddled with untested assumptions.
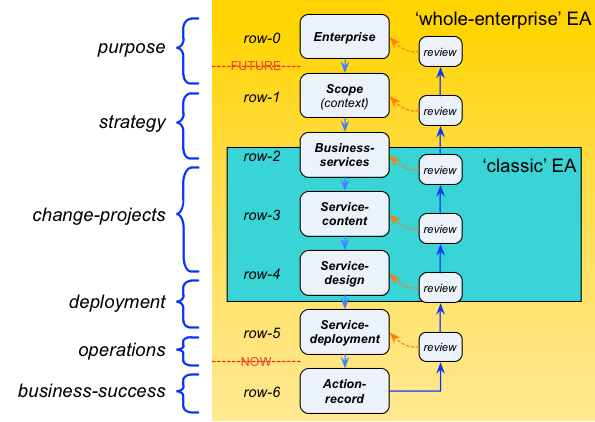
The problem here is that classic ‘EA’ only covers part of the realisation-stack – in Zachman terms, only the ‘logical’ layer, plus some of ‘physical’ and ‘conceptual’, or, as here, extending only a small distance either side of the ‘plan’ (row-3) stage in the classic model for change-projects:
There’s also another related challenge around timescales. Classic ‘enterprise’-architecture tends to operate on an assumed business-cycle, or a technology-lifecycle – somewhere in the range of one to five years at most, anyway. That fits well enough with most of what happens in an IT-centric world, perhaps – but is often ludicrously inadequate for many other real-world contexts. Engineering and defence often work on lifecycle of fifty years or more; healthcare, by definition, must be able to work with the entirety of a human lifetime; and other contexts that need a whole-of-enterprise focus across timescales from sub-microsecond to millennia or more.
To give one simple example, lifecycles for healthcare-IT may be five years or less, whereas healthcare-data for a human lifetime may well need to cover a hundred years or more – which means that we’d need to plan, right from the start, for maybe twenty or more migrations of that data from from one IT-system to another over that human lifetime. If we can’t do those migrations properly over that timescale, we risk losing the data – which could well lead to literally-lethal outcomes. Not A Good Idea…
If we only have a partial architecture, covering only part of the real timescale, how will the whole realisation-process work, with nothing to hold it together? This is a challenge that arises directly because of the inadequate coverage of the architecture-context provided by classic ‘enterprise’-architecture:
Partial architectures are not enough to make this work. If the connections from abstract to real are not complete, all of the architecture-scope and across all requisite timescales, the architecture will fail!
Another key theme here: To support continual iterative-improvement, architecture and design must support the entire lifecycle – not just the ‘easy bit’ of making plans for others to follow and finish off. In other words, the realisation-stack isn’t complete unless we fully include and connect with build, run-time, task-outcomes, and decommissioning too:
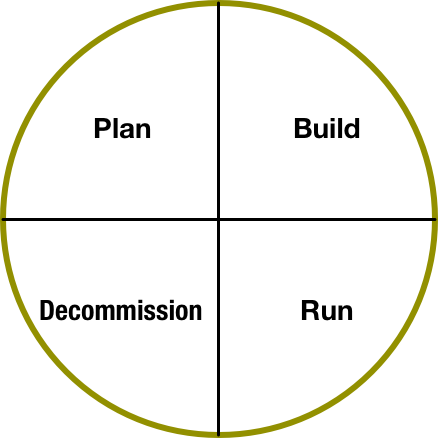
In architecture done wrong, the typical attitudes from architects and designers alike might be:
- Plan: We do this bit!
- Build: We tell others how to do this bit
- Run: Not our problem – let them deal with it
- Decommission: (No idea – it’s nothing to do with us)
…whereas in architecture done right, the attitudes would need to be:
- Plan: We do part of this bit!
- Build: We advise others on the architectures for this bit
- Run: We learn from this bit
- Decommission: We are also responsible for this bit
The architecture must include appropriate exploration of how things to be designed and built will be decommissioned at the end of their use or lifecycle. For example, one simple guideline: If you can’t decommission it, don’t build it!
If decommission is ignored, the plan/build process will become a metaphoric machine for creating unaddressed technical-debt – so again, decommissioning must be included in the architecture!
One further way to make sense of the issues here, and also how to avoid those traps, is to describe it in terms of the sequence of activity-phases in the classic TOGAF ADM (Architecture Development Method):
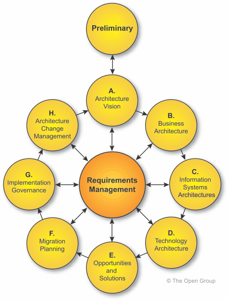
In TOGAF done wrong, these are the attitudes about the respective phases that we tend to see:
- Phase A: Tedious paperwork that doesn’t matter and no-one reads
- Phase B/C/D: Where we get to do the fun bit!
- Phase E: The final design, done by us, which is perfect, of course
- Phase F/G: The boring bit where we have to keep telling people that they’ve got the design wrong
- Phase H: We’ve finished that cycle, so now it’s time to look at all the shiny new toys!
In contrast, in TOGAF done right, the attitudes and awareness of responsibilities are significantly different:
- Phase A: Essential setup to connect to previous architecture work
- Phase B/C/D: Our part of the architecture responsibility
- Phase E: Demonstrator design to show how to align to the architecture
- Phase F/G: Help people ensure that their designs and design-choices do align with architecture constraints and guidelines
- Phase H: Benefits realised, lessons-learned, tasks to reduce technical-debt
We need to address those issues properly – even within classic ‘enterprise’-architecture.
And we also need to address the very real consequences of classic ‘enterprise’-architecture having such an arbitrarily-constrained scope – because if the full scope of architecture from most-abstract to most-real is not properly addressed, the overall architecture will fail. So if classic ‘EA’ must run as a separate entity (the blue section in the graphic below), it must ensure that it has adequate hooks into all of the other parts of the realisation-stack (the yellow section in the graphic) that are presumably somehow managed and maintained by other business units:
Again, if the whole scope of the realisation-stack is not properly addressed, the architecture as a whole will fail.
To summarise, How to avoid Fail #2: Starting architecture too late and/or finishing too early:
- Ensure that the whole realisation-stack is fully covered
- If your architecture covers only part, establish hooks to connect to the rest
- Include run-time and decommission in the overall architecture
For the final post in this brief series, we’ll explore how to avoid Fail #3: Placing arbitrary constraints on content, scope and/or scale.
Leave a Reply